Currently open for review, please send feedback to oi.atut@xisraeg
The C programming language has been popular since its birth during the 1970s at Bell Labs. Today, C is still popular - remaining in the top two positions of the TIOBE index1. So it's not unlikely that you might find yourself using C.
If you're using C, then you're inevitably going to end up using it's memory allocation features found the stdlib.h (unless your sticking to some strict guidelines - like MIRSA C). Handling memory like this requires some discipline, even with that discipline you'll make mistakes (albiet it's much easier to avoid these mistakes today with tools like Valgrind and Clang's -fsanitize).
There are a few typical rules to follow when handling memory in C to avoid making these mistakes: don't assign more memory than is available, make sure you deallocate all allocated memory, only deallocate allocated memory, etc.
To avoid these pitfalls and complete rewrites, developers employ various tactics to keep track of & control access to memory within their C runtime.
What Memory?
First, lets define memory. Here's how the C Standard defines memory storage
:
An object has a storage duration that determines its lifetime. There are three storage durations: static, automatic, and allocated.3
Automatic memory is used for local variables (e.g. int i = 1;).
This memory doesn't require explicit allocation/deallocation beyond it's declaration & assignment.
Modern languages that use garbage collection treat all variables as automatic memory.
Static memory is used for variables that have been declared using the storage-specifier keyword static.
Its lifetime is the entire execution of the program and its stored value is initialized only once, prior to program startup
2.
A local variable with a global lifetime.
Allocated memory is memory explicity requested for allocation by the developer. The C standard library provides functions in the stdlib header to do this with methods like malloc. System calls, like mmap4 on POSIX-compliant systems can also be used.
So automatic and static memory aren't managed by the developer, instead the system hosting the runtime manages these - this memory is commonly referred to as the stack. The developers main concern in regards to memory management is allocated memory, this is commonly referred to as heap-allocated memory.
The terms "stack" and "heap" are typical methods used by (mostly older, specifically Unix) operating systems for managing the different types of memory in C. They provide a nice model to discuss memory in a C runtime and are referred to as the C memory model.
It's important to note that the ISO C Standard doesn't make any reference to the terms "stack" or "heap" in the C specification.
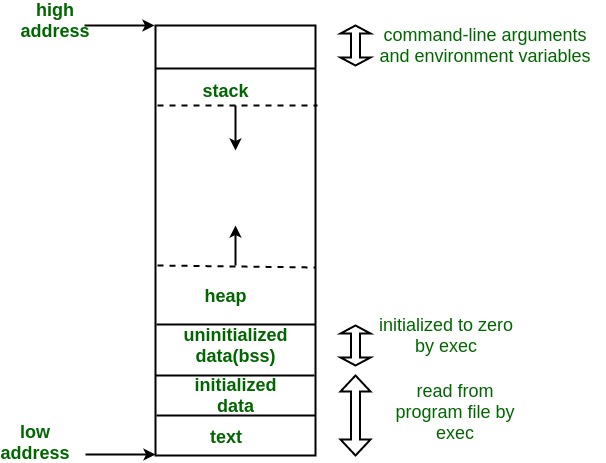
The above image is how memory is laid out in this model. The text, data and bss segments in the image are static and built into the binary:
- text (sometime referred to as code) section contains assembly instructions to be executed.
usually marked read-only so a program can't modify its own instructions.
5 - init (data) is where all initialised global and static variables are found. Not read-only, since global/static variables can be modified during runtime (unless const).
- uninit (bss). All the data above that isn't initialised.
All variables in this segment are initialized to 0 or NULL pointers before the program begins to execute.
5
Checking the size of these sections just requires reviewing the binary before running it.
You can check this really easily on POSIX machines with the the size command:
$ size a.out
text data bss dec hex filename
1577 560 8 2145 861 a.out
The stack refers to an area of memory used for system-allocated memory (the earlier discussed automatic and static memory). Its name derives from an implementation using the stack data structure, starting at a high memory address and growing towards low memory addresses. Variables are pushed/popped on/off the stack as they enter/exit scope during runtime.
The heap is the name for memory dynamically allocated & free'd as requested by the developer - this is the allocated memory type. This area of memory grows & shrinks from a low address towards higher addresses as requested by the program during runtime.
So the only memory a developer is directly responsible for managing is (heap) allocated memory. Lets look ways to do this.
Explicit management
This method has been named explicit because it makes it obvious to anybody reading the code how the amount of allocated memory is tracked and where the data tracking it is kept. Everything is done explicitly and manually (which very much fits the ethos of the C language).
To do this, information about the size of an allocated block is kept along with a pointer to the block itself. This can be easily done with a struct.
#include <stdlib.h>
#include <stdint.h>
struct buffer {
uint8_t *buf;
size_t siz;
};
int main()
{
struct buffer b = { malloc(24), 24 };
b.buf = realloc(b.buf, 28);
b.siz = 28;
free(b.buf);
}
buf points to the allocated memory block of uint8_t (unsigned 8-bit integer) data. siz keeps track of the size of the memory block buf points to.The advantages to this method are that it's explicit and has minimal overhead - anybody reading the code can see what's going on at a glance. In most situations it's ideal, although verbose. Usually developers will write a small wrapper library that bundles allocation and updating size data into a set of function calls.
The disadvantage of this method is when scope becomes complicated. You want to make sure you're able to keep access available to all tracked allocations whenever you need it. How can you do that if a static allocation is made in a seperate function call? Or in a seperate thread? Or any other scope you might not have access to?
- A bad solution is to just keep all allocated memory and count of that memory, global. Due to how bad this idea is, it probably shouldn't be considered a viable solution in most cases, unless you're codebase is tiny. See Cunningham & Cunningham, Global Variables Are Bad5.
- As always, well structured and good code is the best solution. Although it's rare to have this much control over a codebase, unless there are a limited number of developers.
So tracking memory allocations locally is easy but tracking memory allocations globally can become difficult and the identified solutions to this are either: bad or rare.
Pooling
Pooling is a another method of tracking & managing allocated memory. Unlike the explicit method, pooling can be a fully-formed memory management system. In the explicit method, it was mentioned that it's common to find a small library of functions that wrap around memory management, this is where you'll find pooling implemented, so these two methods aren't always distinct.
It's not uncommon to see the act of allocating memory on a system be slow, so a good way to optimize this is to minimize the number of allocations made by just allocating memory in large blocks (pools), then whenever a chunk of memory is needed, reserve it from the allocated pool. Likewise, when use of that chunk is finished, it's unreserved and can be re-used the next time memory is requested.
The issue in this method comes in the complexity of its implementation. One of the biggest difficulties is dealing with memory fragmentation: imagine a 10-byte pool is allocated (0..9); 3-bytes are reserved for the first buffer (0..2); 5-bytes of the pool are reserved for another buffer (3..7). Then you decide to free the first buffer, now bytes 0..2 and 8..9 are free but 3..7 are reserved. If you need to reserve another contiguous chunk larger than 3 bytes (0..2), then you need to make an other pool allocation, increasing the size of the pool to 0..19, despite having 5 bytes free (but seperated in two blocks). This is a problem that becomes more complex with larger runtimes, which can become very inefficient and solutions to it add another layer of complexity (which is more potential for bugs).
A good way around the issue of memory fragmentation is to limit the reservations that can be made into fixed-size chunks (or objects). This method is useful where objects are allocated/deallocated frequently, although it requires the objects to be of the same size per-pool to avoid fragmentation again. An example of fixed-size object pool allocation is provided in a small text buffer library I wrote, see gearsix, piece-chain7 - all chunks are a fixed-size objects (Pieces), this allows the allocator to free/reserve chunks without worrying about memory fragmentation because the chunks are all the same size.
An implicit method
So explicit allocation is very easy to implement and keeps details of it's implementation clear but it doesn't work great at scale. Pooling is a great solution where memory management is a core detail and more a refined implementation is needed but comes at the cost of adding complexity.
As a solution that lies inbetween the two, I recently decided to experiment with a method of handling memory that avoids the complexity of pooling and fixes the scaling issue in explicit allocation, unfortunately it's got a terrible name: tralloc - track allocations8.
The idea is to have a small wrapper around the stdlib.h memory allocation functions that acts as a thin layer adding size metadata to allocations made. This is done by adding the size of a block, using a size_t to the start of every allocated block. The allocated block is returned from the first byte after the size information, allowing it to be treated as a regular memory block returned from stdlib.h. On top of adding allocated size information to every allocated block, a size_t is kept to keep track of the total amount of allocated memory, as well as a limiter that stops allocations beyond a set amount.
#include <stdlib.h>
void *tralloc(size_t n)
{
size_t *ptr = 0;
n += sizeof(size_t);
ptr = malloc(n);
ptr[0] = n;
return &ptr[1];
}
malloc wrapper.The libray allows you to check the size of a tralloc-allocated memory blocks by calling tr_allocsiz(ptr); it allows you to check the total allocated memory by calling tr_siz() and you can set a limit on the amount of allocated memory by calling tr_setlimit() and check that value by calling tr_limit().
The downsides of this library are that it implements some pointer trickery by taking advantage of being able to out-of-bounds with pointers, i.e. the tr_free() function free's the passed pointer from ptr[-1] because the allocations are returned from ptr[1]. This is obviously dangerous and requires you to be as careful with a tralloc pointer as you would be with a malloc pointer (probably even more careful).
Overhead
The overhead (amount of additional memory used for tracking information) of tralloc is intended to be minimal.
All size tracking is done using size_t variables, which is an unsigned integer type of the result of the sizeof operator
3. Whether it's an unsigned long int (32bits) or an unsigned long long int (64bits) depends on your compilation target. The implication behind a size_t is that it's suppose to be able to hold the size of any data.
To calculate memory usage...
Consider the set of allocated memory blocks to be b.
By default the amount of memory used in a runtime is the m(b), the sum of all b:
m(b) = ∑(∀b).
The overhead of using tralloc is an additional size_t (named s) for every b, plus the two for tracking global memory usage:
o(b) = s * (|b| + 2).
So the allocated memory usage using tralloc (u(b)) is:
u(b) = m(b) + o(b) = ∑(∀b) + (s * |b| + 2).
disclaimer I haven't done mathematical notation in a long time, so this might be badly formed or outright wrong. If you know either way, drop me an email!
Conclusions
A review of the different types of memory allocation: static, automatic and allocated; the concept of the "C Memory Model"; as well as three different methods of managing allocated memory, their advantages and distadvantages: the explicit method is very quick & easy way of tracking allocated memory, but struggles with scale; pooling is really a full-on memory management system - great where memory management is a core component, but it introduces a lot of complexity.
The main purpose here was to introduce how the tralloc library works, which is a solution that sits somewhere inbetween the other two. It's not fully-formed enough to provide an entire memory management system like pooling, but instead provides tracking of allocated memory without becoming a hassle at scale. The actual implementation of the library is only a proof-of-concept and there's certainly room for improvement, so it's not recommended for use in production.
If you found this article useful or can provide feedback / improvements, please feel welcome to and drop me an email.
References
-
The TIOBE Programming Community index is an indicator of the popularity of programming languages. The index is updated once a month. Thse ratings are based on the number of skilled engineers world-wide, courses and third party vendors. Popular search engines such as Google, Bing, Yahoo!, Wikipedia, Amazon, YouTube and Baidu are used to calculate the ratings.
https://www.tiobe.com/tiobe-index/ [Accessed 20 October 2021]. -
ISO/IEC 9899:TC3 N1256 6.2.4 Storage durations and objects 1
-
The Open Group Base Specifications Issue 7, 2018 edition. IEEE Std 1003.1™-2017 mmap - map pages of memory.
Available at: https://pubs.opengroup.org/onlinepubs/9699919799/ [Accessed 22 November 2021] -
GeeksforGeeks, 2021. Memory Layout of C Programs
Available at: https://www.geeksforgeeks.org/memory-layout-of-c-program [Accessed 21 October 2021]. -
Salzman, P., 2021. Using GNU's GDB Debugger Memory Layout And The Stack. p.3.
Available at: https://www.comp.nus.edu.sg/~liangzk/cs5231/stacklayout.pdf [Accessed 21 October 2021]. -
Cunningham & Cunningham, July 31, 2013. wiki.c2.com Global Variables Are Bad.
Available at: http://wiki.c2.com/?GlobalVariablesAreBad [Accessed 22 November 2021] -
gearsix, July 2022. piece-chain
This is the implementation of a Piece Table where I used pool allocation, with a system for recycling allocated memory. Seepieceblk,freeblk,pallocandpfree. Available at: https://notabug.org/gearsix/piece-chain/src/master/buf.c [Accessed 25 July 2022] -
gearsix, Dec 2021. tralloc
tralloc is a stdlib.h wrapper that keeps track of the size of allocated memory blocks, as well as the total amount of allocated memory. Available at: https://notabug.org/gearsix/tralloc/ [Accessed 25 July 2022]